Wir haben in den letzten Jahrzehnten enorme Fortschritte durch künstliche Intelligenz (KI) gesehen. Dieser Fortschritt wurde jedoch nicht stetig erreicht. Es gab erhebliche Höhen und Tiefen auf dem Weg. In einigen dieser Phasen hatten die Menschen sogar Angst, sich offen für den Begriff künstliche Intelligenz zu engagieren, da der Ruf des Fachgebiets stark beschädigt war. Jeder, der an KI arbeitete, galt zu dieser Zeit als Träumer. Dies führte auch dazu, dass verschiedene Namen und Unterteilungen des Feldes als maschinelles Lernen, Data Mining oder Mustererkennung aufkamen.
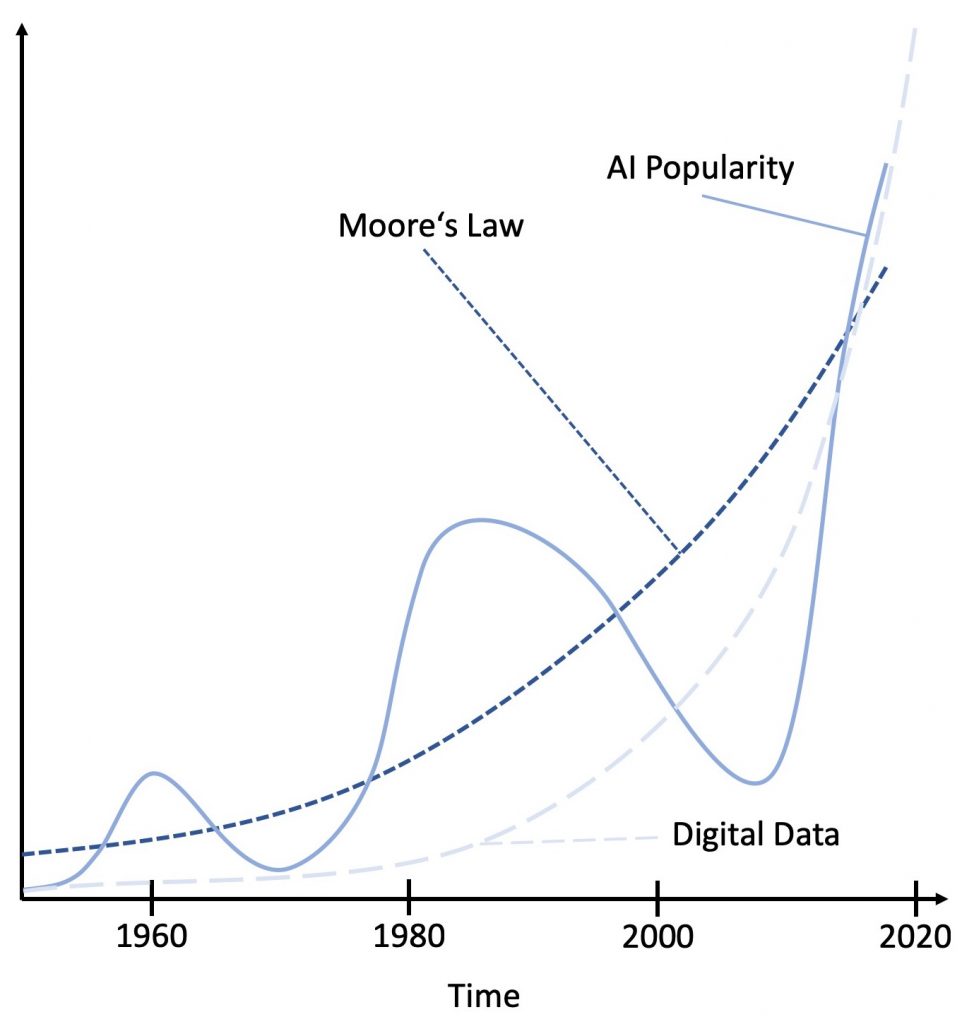
In einem kürzlich erschienenen Blogpost von Richard Sutton wurde der Mangel an Rechenleistung als wesentlicher Grund für die Höhen und Tiefen, die bisher angetroffen wurden, identifiziert. In seiner gründlichen Analyse wird festgestellt, dass allgemeine Modelle, immer Modelle übertroffen haben, die hauptsächlich auf Expertenwissen beruhten. Mit zunehmender Rechenleistung konnten die allgemeinen Modelle die handgefertigten, auf Expertenwissen basierenden Modelle übertreffen. Zu dem Zeitpunkt, an dem allgemeine Modelle zu rechenintensiv wurden, schlug Moores Gesetz zu und weitere Fortschritte mit allgemeinen Ansätzen wurden unmöglich. Abbildung 1 zeigt diese Entwicklung schematisch. Basierend auf dieser Analyse wird die Schlussfolgerung gezogen, dass die Einbeziehung von Expertenwissen eine Verschwendung von Ressourcen darstellt, da nur gewartet werden muss, bis genügend Rechenleistung zur Verfügung steht, um den nächsten Meilenstein in der Maschinenintelligenz zu lösen. Diese Schlussfolgerung ist radikal und verdient etwas mehr Analyse. Daher werden wir eine kurze historische Perspektive haben, d.h. eine kurze Zusammenfassung von drei Artikeln, die kürzlich auf KDnuggets veröffentlicht wurden.
Der erste erste KI-Hype begann in den 1950er Jahren und führte zu wichtige Entwicklungen auf dem Gebiet. Minsky entwickelte die erste neuronale Netzwerkmaschine namens Stochastic Neural Analogy Reinforcement Computer (SNARC), die vom biologischen Design inspiriert war und Neuronen in eine elektrische Maschine abbildete. Weitere wichtige Entwicklungen waren das Perceptron, das biologisch inspirierte Neuronen in einem Computerprogramm trainierbar machte. Eine weitere wichtige Entwicklung dieser Zeit war die Erfindung regelbasierter Grammatikmodelle, mit denen die ersten einfachen Aufgaben zur Verarbeitung natürlicher Sprache gelöst wurden. Auch das Konzept des Turing-Tests fällt in diese Zeit der KI. Mit diesen großartigen Entwicklungen wuchsen die hohen Erwartungen an die KI allmählich schneller und schneller. Diese Konzepte konnten jedoch ihre Erwartungen nicht erfüllen und scheiterten in vielen Anwendungen des täglichen Lebens. Diese Zweifel wurden weiter durch theoretische Beobachtungen gestützt, z.B. dass das Perceptron die logische XOR-Funktion nicht lernen kann, da sie nicht linear trennbar ist. Infolgedessen wurden die Mittel für KI enorm gekürzt, was heute auch als KI-Winter bekannt ist.
In den 80er Jahren kehrte die Faszination der KI zurück. Dieser zweite Boom wurde durch die Entwicklung wichtigerer Techniken wie des Back-Propagation-Algorithmus, der Multi-Layer-Perceptrons trainierbar machte, und der theoretischen Beobachtung, dass ein neuronales Netzwerk mit einer einzelnen verborgenen Schicht bereits ein allgemeiner Funktionsapproximator ist, gefördert. Es wurden wiederkehrende Netze entwickelt und das Lernen durch Verstärkung (engl. "Reinforcement Learning") machte die Spieltheorie auch trainierbar. Ein weiterer Durchbruch dieser Zeit war die Entwicklung statistischer Sprachmodelle, die allmählich regelbasierte Systeme ersetzten. Sogar tiefe und Faltungsnetzwerke wurden zu dieser Zeit bereits erforscht (engl. "Deep Learning"). Der stetig wachsende Rechenaufwand - unterstützt durch numerische Instabilitäten - führte jedoch zu langen Trainingszeiten. Gleichzeitig entstanden andere modellbasierte, weniger komplexe Techniken wie Support Vector Machines und Ensembling, die die Bedeutung neuronaler Netze allmählich verringerten, da dieselben oder bessere Ergebnisse in kürzerer Zeit erzielt werden konnten. Insbesondere konvexe Optimierungs- und Variationsmethoden wurden zu wichtigen Konzepten, die diesem zweiten KI-Hype ein Ende setzen. Zu dieser Zeit war "allgemein bekannt", dass neuronale Netze ineffizient und numerisch instabil sind. Viele Forscher würden ihre Zeit nicht mehr in diese Richtung investieren, da andere Methoden effizienter waren und Daten effizienter verarbeiten könnten.
Die dritte Hype-Periode, die wir derzeit erleben, ist wieder angetrieben von vielen wichtigen Durchbrüchen. Wir haben gesehen, wie Computer erstklassige Go-Spieler besiegten, Kunst schufen und zuvor nahezu unmöglich erscheinende Aufgaben wie Bildunterschriften lösten. Ein wiederkehrendes Hauptthema in dieser Zeit ist, dass Handarbeit und Feature-Engineering nicht mehr erforderlich sind und Deep-Learning-Algorithmen alles sofort lösen. Tatsächlich wurden wichtige Konzepte entdeckt, die wir auf viele moderne Ansätze verallgemeinern können. Tiefe Faltungsnetzwerke haben mehrskalige Ansätze wie die SIFT- und die Wavelet-Theorie ersetzt. Außerdem haben trainierbare Faltungs-Neuronale Netze gezeigt, dass sie sogenannte Mel-Frequenz-Cepstrum-Koeffizienten (MFCCs) in der Sprachverarbeitung übertreffen, wenn diese Merkmale das Feld seit fast 50 Jahren dominieren. Es scheint, dass ein Großteil der Theorie, die in der Vergangenheit entwickelt wurde, ist obsolet geworden. Man muss jedoch bedenken, dass das tiefe Netzwerkdesign tatsächlich häufig von den klassischen Merkmalsextraktionsmodellen inspiriert ist und dass Bildverarbeitungsmerkmale deutliche Ähnlichkeiten mit Wavelet-Transformationen aufweisen und Audioverarbeitungsnetzwerke immer noch implizite Filterbänke bilden. Als solches ist das Wissen immer noch da, aber es ist in einer anderen Form codiert. Dennoch muss man anerkennen, dass die trainierbaren Versionen früherer Algorithmen ihre Vorgänger deutlich übertreffen.
In unserer aktuellen Analyse fehlt eine dritte Komponente, die einen weiteren Treiber für den heutigen Erfolg in der KI darstellt: die Verfügbarkeit digitaler Daten für das Training der Algorithmen für maschinelles Lernen (vgl. Abbildung 1). In einem kürzlich erschienenen Artikel beobachten Helbing und Kollegen, dass Daten sich alle 12 Monate verdoppeln, während sich sogar die GPU-Verarbeitungsleistung sich "nur" in 18 Monaten verdoppelt. Infolgedessen werden wir bald nicht mehr in der Lage sein, Daten so umfassend zu verarbeiten wie heute. Wir haben entweder die Möglichkeit, nur eine begrenzte Datenmenge zu verarbeiten, oder wir müssen die Komplexität der Ansätze, mit denen wir sie verarbeiten, begrenzen. Infolgedessen könnten modellbasierte Ansätze bald wieder die Oberhand gewinnen und wir könnten eine weitere Periode erleben, in der nicht allgemeine und spezialisierte Modelle die Forschung vorantreiben werden.
Diese Art der Forschung scheint vergeblich, da sie irgendwann durch allgemeinere Modelle ersetzt werden kann. Wir müssen jedoch einen weiteren wesentlichen Vorteil von Modellen berücksichtigen: Sie können entsprechend verstanden und manipuliert werden. Nehmen Sie zum Beispiel eine physikalische Formel, die nach der einen oder anderen Variable gelöst werden kann. Wir können dies mit allen Modellen durchführen und ihre Eigenschaften verwenden, um sie für neue Verwendungszwecke neu anzuordnen. Dies ist etwas, was wir mit gegenwärtigen Deep-Learning-Modellen nicht tun können. Sie müssen von Grund auf neu trainiert werden und können nur begrenzt wiederverwendet werden. Da solche Modelle auch viel zu bieten haben, was aktuelles Deep Learning nicht kann.
Für die ferne Zukunft können wir bereits spekulieren, dass eine solche wissensbasierte KI in den kommenden Jahren durch eine echte allgemeine KI ersetzt wird, die in der Lage ist, solche Modelle selbst zu erstellen, zu warten und wiederzuverwenden, wie Sutton vorhersagt. Nach Meinung des Autors dieses Artikels sind Ansätze zur Kombination von Domänenwissen mit tiefem Lernen jedoch nicht umsonst, da die nächste Verallgemeinerungsstufe durch Lehren aus der modellgetriebenen KI erreicht wird, die noch aussteht. Während wir modellgetriebene KI entwickeln, werden wir verstehen, wie man gute trainierbare Modell-KI-Lösungen erstellt und schließlich automatisierte Methoden erstellt, um dasselbe zu erreichen.
Natürlich ist es schwierig, Vorhersagen zu treffen, insbesondere über die Zukunft. Egal, ob es sich um allgemeine modellfreie Ansätze oder modellgetriebene Wissenschaft handelt, wir freuen uns auf die kommenden, spannenden Jahre für maschinelles Lernen, Mustererkennung und Data Mining!
Dieser Text erschien bereits auf englischer Sprache auf MarkTechPost.com. Wenn Ihnen dieser Blog-Beitrag gefallen hat, empfehlen wir Ihnen, unsere anderen Beiträge auf MarkTechPost.com oder Medium zu lesen. Wir empfehlen auch einen Blick auf unsere kostenlosen Deep-Learning-Ressourcen an.
Text und Bilder dieses Artikels sind unter Creative Commons License 4.0 Attribution lizenziert. Fühlen Sie sich frei, einen Teil dieses Texts wiederzuverwenden und zu teilen.
Dir gefällt, was Andreas Maier schreibt?
Dann unterstütze Andreas Maier jetzt direkt: