Die ersten Störungmeldungen tauchten ca. um 17 Uhr den 4.10.2021 auf um 18:22 MESZ twitterte Facebook https://twitter.com/Facebook/status/1445061804636479493 "Wir sind uns bewusst, dass einige Leute Probleme mit dem Zugriff auf unsere Apps und Produkte haben. Wir arbeiten daran, die Dinge so schnell wie möglich wieder in den Griff zu bekommen, und entschuldigen uns für die Unannehmlichkeiten." eine nette Untertreibung. Der Ausfall war wohl weltweit und dürfte Millionen Nutzer betroffen haben.
In Deutschland waren zunächst zwar noch IP-Adressen von Facebook erreichbar, aber später löste facebook.com noch nicht einmal auf eine IP-Adresse auf. Host facebook.com not found: 2(SERVFAIL) hies es dann lapidar. Im Laufe der mindestens fünfstündigen Störung kam es dann noch besser:
Host www.facebook.com not found: 4(NOTIMP)
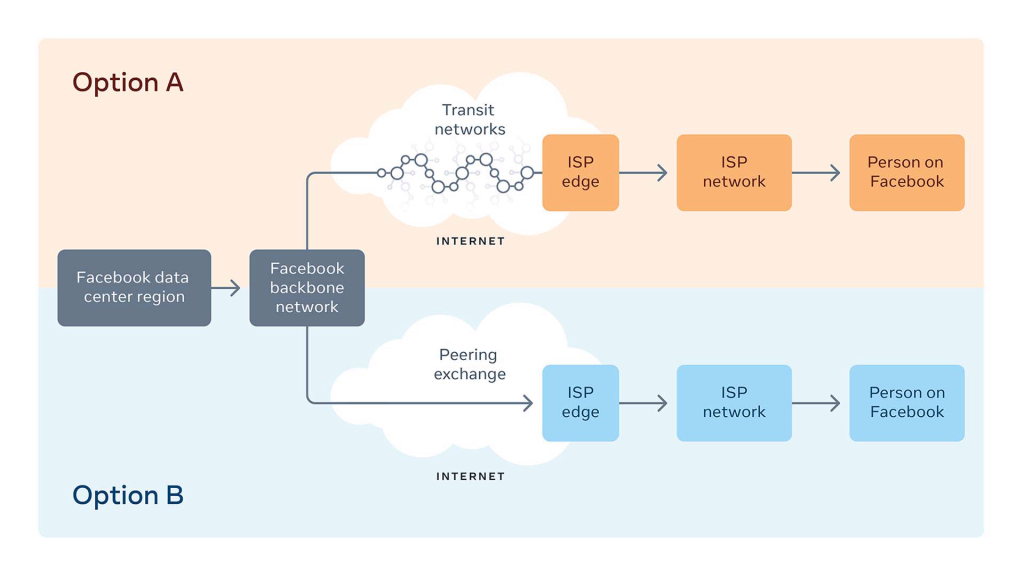
Manche Zeitung titelte sogar, dass facebook.com zum Verkauf stünde. Die Probleme betrafen nicht nur Facebook sondern auch andere Dienste die zum Konzern von Mark Zuckerberg gehören. Es gab und gibt viele Vermutungen, was die Ursache des Ausfalls gewesen sein könnte. Wie Pavel in seinen Thread äussert, könnte es tatsächlich sein, dass diese Technikumstellung https://siliconangle.com/2021/05/20/facebook-automates-network-peering-enable-smoother-web-traffic-management/ Facebook auf die Füsse gefallen ist. Vieles aus dem Fehlerbild passt einfach dazu.
Gerüchteweise heisst es, dass um den Fehler zu beheben Menschen vor Ort in dass Rechenzentrum von Facebook mussten, weil auch im internen Netzwerk von Facebook vieles nicht mehr erreichbar war. Sprich in dem Konzern der Turnschuhadmin zur Ehre kam und Routen manuell zum Laufen gebracht weren mussten. Es wird auch vermutet, dass wir die Wahrheit nie erfahren werden. Tatsache ist allerdings, dass schon die Nachricht "some people" falsch war. Alleine schon die Tweets auf Twitter zu facebookdown waren Millionen. Und es gab auch keinen berüchtigten "Bei mir geht es!" Nachrichten. Bei kleineren Ausfällen insbesondere, wenn es nur ein Land betrifft kommt das vor. Angeblich soll Facebook im Iran funktioniert haben, aber sonst kaum wo auf der Welt.
Ich schreibe hier zwar immer nur Facebook, aber das Problem betraf auch Instagram, Whatsapp und den Messenger. Manche Nutzer verstiegen sich sogar dazu über einen InternetshutDown zu reden. Tatsächlich war die Störung nur beim Facebookkonzern und sonst funktionierte das Internet bestens und ganz hervorragend. Wer als facebookabstinent lebt, war von der Störung gar nicht betroffen. So um Mitternacht deutscher Zeit kamen die Dienste allmählich wieder hoch.
Aber wie von einigen vermutet war es da noch etwas hackelig. Mark Zuckerberg ist zu der Zeit auch Live auf Youtube gegangen. Zum Zeitpunkt dieses Artikels war noch nicht ganz klar, was er zu dem Ausfall sagte. Offensichtlich wollten aber soviel Nutzer von Facebook&Co während der Störung zu einem anderen Soical Media Dienst umziehen, dass Telegram auch leichte Störungen zu verzeichnen hatte, weil dieser Dienst mit dem Ansturm nicht ganz fertig wurde. Der Ansturm auf Twitter hingegen, beeinträchtigte deren Technik offensichtlich nicht.
Der Single Point of Failure bei Facebook überrascht allerdings. Das hätte ich zumindest bei einem solchen weltweit agierenden IT-Konzern nicht erwartet. Das der Ausfall aufgrund eines automatisierten Peeringverfahrens erfolgt, scheint allerdings sehr plausibel. Ohne ein entsprechendes Routing zum Host geht halt gar nichts mehr. Je größer ein Dienst ist, desto mehr braucht er diese Lastverteilung. Somit wurde Facebooks Größe hier zum Verhängnis.
Aber das Internet an sich funktionierte klaglos. Es war nur eine einzige Firma und nur die betroffen. Es zeigt allerdings wieviele Menschen das Internet mit Facebook gleich setzen oder gar nicht wissen, bei welcher Datenkrake sie dort Kunde sind. Es wird sich zeigen, ob der ca. fünf- bis sechstündige Ausfall Facebook überhaupt schadet.
Cloudflare vermeldete dazu "Heute um 1651 UTC eröffneten wir einen internen Vorfall mit dem Titel "Facebook DNS lookup returning SERVFAIL", weil wir uns Sorgen machten, dass etwas mit unserem DNS Resolver 1.1.1.1 nicht stimmt. Doch als wir die Meldung auf unserer öffentlichen Statusseite veröffentlichen wollten, wurde uns klar, dass etwas viel Ernsteres im Gange war." https://blog.cloudflare.com/october-2021-facebook-outage/
Die Vermutung also, dass es sich um die neu eingesetzte Technik bei Facebook als Ursache handelt, dürfte sich als richtig erweisen. BGP ist dabei alt, aber das automatisierte Verfahren ist neu. BGP steht für Border Gateway Protocol. Es ist ein Mechanismus zum Austausch von Routing-Informationen zwischen autonomen Systemen (AS) im Internet. Die großen Router, die für das Funktionieren des Internets verantwortlich sind, verfügen über riesige, ständig aktualisierte Listen möglicher Routen, über die jedes Netzwerkpaket an sein endgültiges Ziel geleitet werden kann. Ohne BGP wüssten die Internet-Router nicht, was sie tun sollen, und das Internet würde nicht funktionieren. Dadurch, dass die Routinginformationen verloren gingen und das Facebooknetz nicht erreichbar war, hat es eine Weile gedauert. Laut cloudflare kamen die Routinginformationen von Facebook, WhatsApp und Instagram um 21:28 UTC wieder zurück und das Unternehmen war mit dem globalen Internet verbunden und sein DNS funktionierte wieder.
Facebook erklärte dazu: "Unsere Ingenieurteams haben herausgefunden, dass Konfigurationsänderungen an den Backbone-Routern, die den Netzwerkverkehr zwischen unseren Rechenzentren koordinieren, Probleme verursacht haben, die diese Kommunikation unterbrochen haben. Diese Unterbrechung des Netzwerkverkehrs hatte einen kaskadenartigen Effekt auf die Art und Weise, wie unsere Rechenzentren kommunizieren, und brachte unsere Dienste zum Stillstand."
Dir gefällt, was Arnold Schiller schreibt?
Dann unterstütze Arnold Schiller jetzt direkt: